Review - NewsQs | Multi-Source Question Generation for the Inquiring Mind
Review - NewsQs: Multi-Source Question Generation for the Inquiring Mind
A paper on a dataset. No means an expert on datasets or machine learning. Dataset generation is interesting :)
Some background
Datasets are hard to make (especially correctly). This paper presents a finetuned model that produces questions that are more human (based on a news dataset the authors created “NewsQs”)
Into the paper
The paper introduces the dataset immediately. It contains News On the Web dataset and uses a QNLI model to discard low quality samples. The existing datasets try to tackle a harder problem “qMDS” (query-based multi-document summarization) that has multiple source documents, questions about them and then long answers to those questions. NewsQs is trying to ask questions for these multiple source documents.
Ok into the datasets

What is going on the @@@@@ haha, and what is Caron? I guess this is what is in the answer already?
It’s nice to see all these models’ outputs. However, I immediately notice that they’re pretty small models. Interesting. Where’s ChatGPT, GPT4, Sonnet, etc…? (I feel like this statement sparks flames with everyone in the field, haha). But even other open source big models such as Mistral 7x8 MoE, llama 1, 2, 3 etc…
But it’s cool that T0-3B and T0pp (basically latest modifications of T5?) are doing well.
BART is verbose & annoying, and it’s actually kind of just rephrasing things. Interesting.

Who wrote the summary? I feel like it’s more of just a recording and the person was writing on the fly. (more like notes rather than summary). Maybe update with big model or filter out I would say.
Actually not sure what the Control Codes are doing here, I’ll have to read back.
All the models seemed to answer it instead of generating questions?

Oh cool. This is like flash card question/answer generation. Nice stuff. And it seems to get important/general questions out? Not sure how to generate general vs specific questions, but would be interesting to control that (maybe something like how instruction tuning works with chat models, so prompt in beginning with something like SPECIFIC QUESTION or GENERAL QUESTION)
Anyways back to the paper section 3.2.

Interesting to finetune T5-Large. Could finetune big model with bitsandbytes with QLoRA quantization. I wonder how it would compare?
Anways, Why these learning rates and epochs? I guess to find the best one, but why that learning rate specifically? More for my understanding of the graph and how learning rate affects how well the model performs. Loss and KL diverage? Idk.
Control codes is similar to instruction tuning, I think? Not sure.
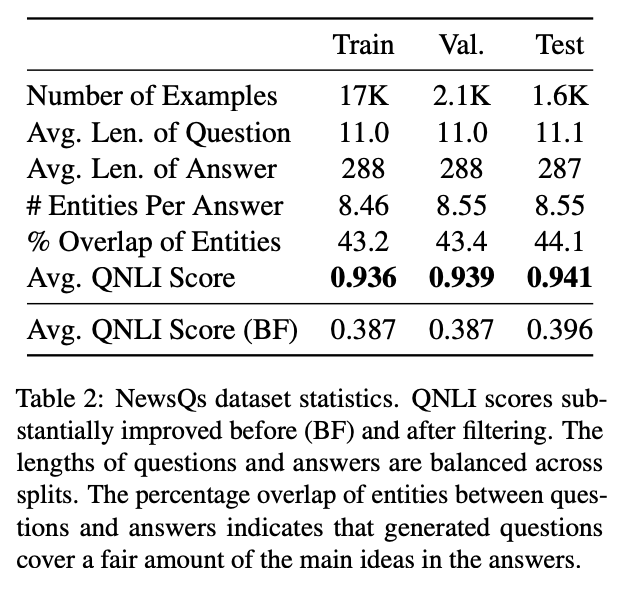
Good results. The test/val set is pretty much the same as train (in sampled space, so uniform dataset). Weird that val/test is a little higher for both before and after, but close enough.

Ok, that’s cool. Using human annotators to evalutate! Besides just the score. Then to categorize the question & good/bad. This is the interesting part to me.

Four annotators total. No idea what Cohen’s Kappa score is. What is the example of each score given to the annnotators?

Interesting that the QNLI model can be used for filtering. Why not train a model like RLHF to filter using the annotator’s responses instead and see how it compares?

Huh, it’s like a RAG. Providing the question, answer and sources to back up the claim. Not sure how the documents are matched with the answer… (like how is it determined) and then anser to question?
Dataset/Model not released, but that’s fine since it’s from industry.
Conclusion
Interesting paper… I’ve never read a human annotated dataset before. There’s a lot going on here. I think the dataset is machine generated, but verified with human annotators which is a cool idea (to ensure that the machine generated question are is not just made up…)
Ideas to improve
Please put this out on reddit/hackernews/whatever.
I think the human annotators’ data is super important. Could be used to train another model to see if generated question is good. Maybe kinda like GaNs (like one says if generated question makes sense or not and to filter)
Needs a bit more background on each term, but that’s not the fault of authors since I’m not an expert (I’m having a hard time following what the different scores/probabilities mean)
Enjoy Reading This Article?
Here are some more articles you might like to read next: