Network and Storage Benchmarks for LLM Training on the Cloud

AI usage has become universal. Teams everywhere are building RAG, generating embeddings, and training increasingly sophisticated agents.
Most distributed LLM training guides focus on model architecture and hyperparameters while ignoring a critical bottleneck: infrastructure configuration. Network and storage choices often determine whether training takes hours or days.
I ran benchmarks finetuning Gemma 3 12B and GPT-OSS-120B with different storage and network configurations using SkyPilot for infra and Nebius for GPUs. The results reveal that InfiniBand networking provides 10x faster training than standard Ethernet, while optimal storage selection can speed up checkpointing by almost 2x. Combined, these infrastructure optimizations deliver 6-7x end-to-end speedup alone.
Some background on training bottlenecks
Here’s something that surprises most people new to large-scale training: your GPUs are most likely not the limiting factor. Modern accelerators like H200s will happily consume whatever data you can feed them. The real challenge is keeping them fed.
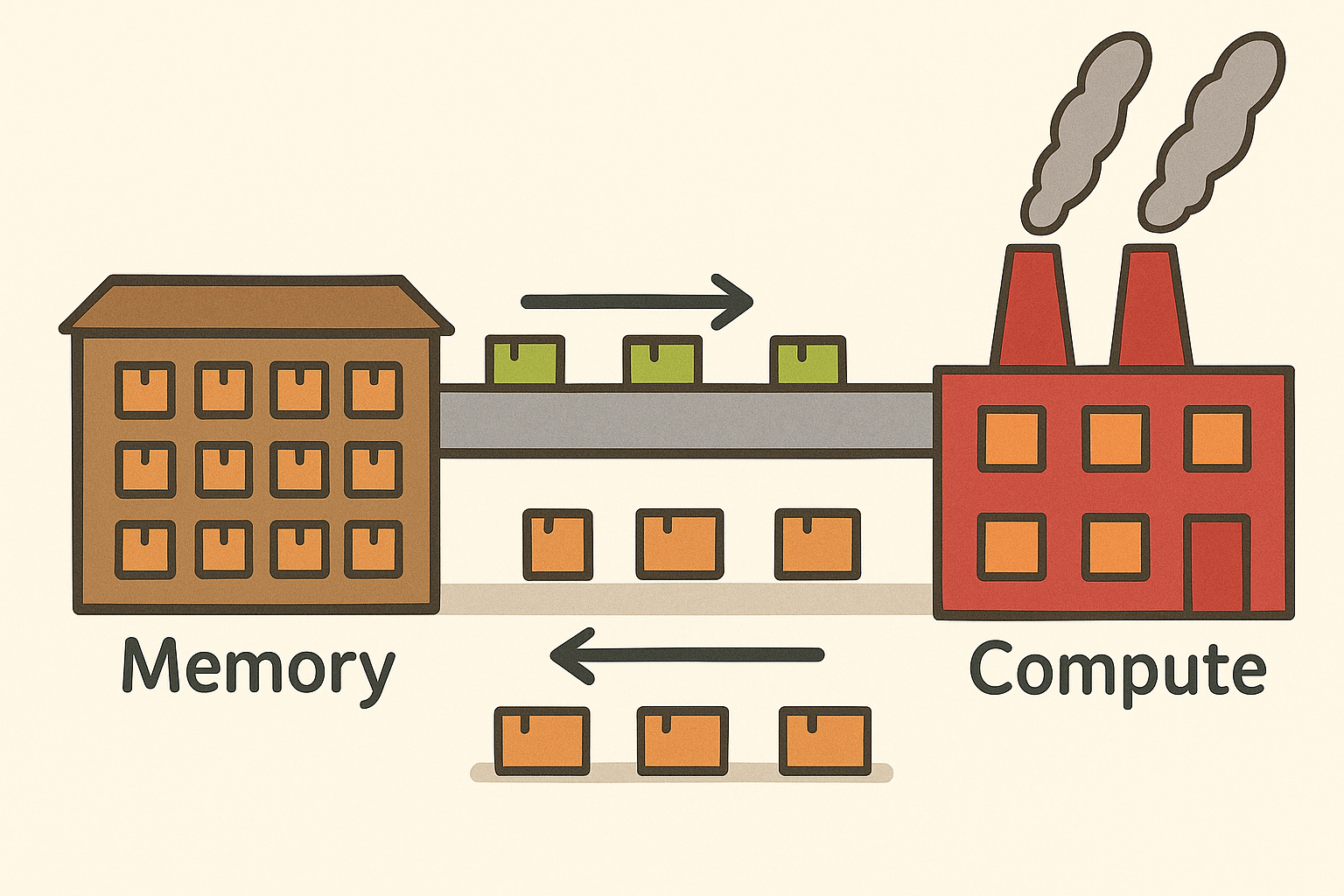
Think of your GPU as an extremely efficient factory. It can process raw materials (your data) at incredible speeds, but it depends entirely on a steady supply chain. Your storage systems hold the raw materials, and the bandwidth between storage and compute acts as the conveyor belt. These days, that conveyor belt has become the constraint.
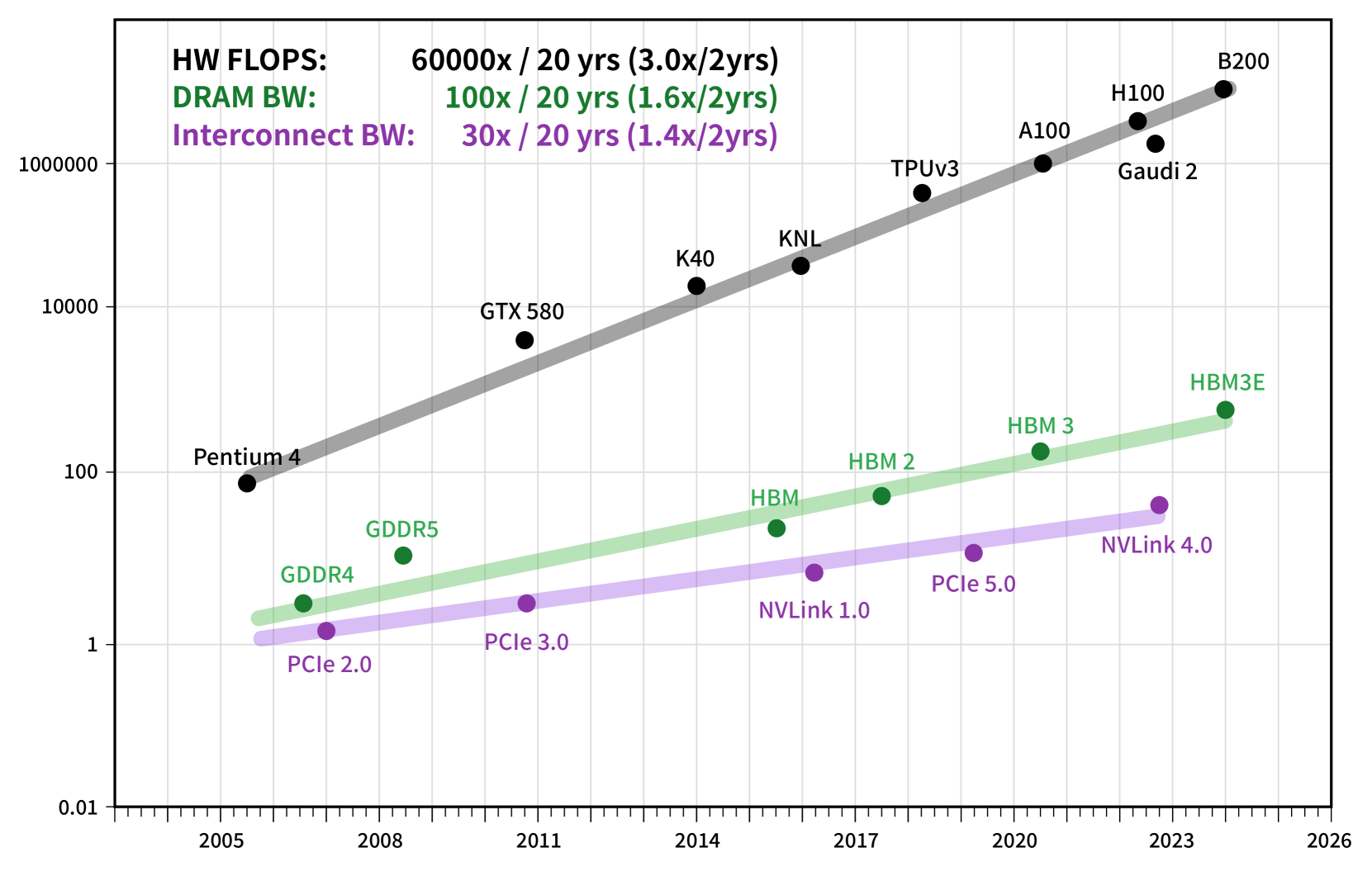
While GPU compute capability has grown exponentially, memory bandwidth and network speeds have followed a more modest trajectory.
The two levers you control
When running distributed training, you have meaningful control over two critical components: storage and networking, especially when running on cloud GPUs.
The objective is straightforward: maximize GPU utilization (or in other words, minimize GPU idleness). But achieving this requires understanding how data flows through your training pipeline and where bottlenecks typically emerge.
The training data flow
During training, data moves through these stages:
- Load batches from dataset – storage
- Communicate gradients between nodes – network
- Dump checkpoint to save progress – storage
In any of these steps, bottlenecks can emerge. For example, loading datasets from or saving checkpoints to storage might take extraordinarily long and block GPU progress. Or the inter-node network bandwidth might be insufficient for communication operations (to synchronize weights/gradients).
Performance benchmarks
I’ll use two concrete examples throughout:
- Google Gemma 3 12B on 2 nodes × H100:8 GPUs
- OpenAI GPT-OSS-120B on 4 nodes × H200:8 GPUs
I ran some experiments on Nebius, a golden GPU provider in SemiAnalysis’s GPU cloud ClusterMax benchmark, to quantify these effects.
Click to see experimental setup
Gemma 3 12B IT Configuration| Component | Specification |
|---|---|
| Cloud Provider | Nebius |
| Model | Gemma 3 12B IT (Hugging Face) |
| Nodes | 2 |
| GPUs per Node | 8x H100s |
| Total GPUs | 16x H100s |
| CPU Memory | 1.5 TB |
| Framework | Hugging Face Accelerate with FSDP |
| Component | Specification |
|---|---|
| Cloud Provider | Nebius |
| Model | GPT-OSS-120B |
| Nodes | 4 |
| GPUs per Node | 8x H200s |
| Total GPUs | 32x H200s |
| Framework | Hugging Face Accelerate with FSDP |
| Configuration | Specification | Theoretical Bandwidth |
|---|---|---|
| Default Ethernet | 10 Gbit/s NIC | ~1.25 GB/s |
| InfiniBand | 400 Gbit/s NIC × 8 cards | ~400 GB/s |
| Storage Type | Description | Performance Profile |
|---|---|---|
| Network SSD | network_ssd_non_replicated | Standard cloud block storage |
| Nebius Shared Filesystem | Nebius's distributed file system offering | High-performance distributed storage |
| Object Store (MOUNT) | Direct S3-compatible mounting | Cost-effective but high-latency |
| Object Store (MOUNT_CACHED) | SkyPilot's cached mounting | Logs to local disk streams to object store |
Network benchmarks: The 9x performance difference
I compared two network configurations:
- Standard 10 Gbit/s Ethernet (the default on most clouds)
- InfiniBand 400 Gbit/s with 8 NICs (high-performance networking)
The raw bandwidth difference is substantial: 1.25 GB/s versus approximately 400 GB/s. But how does this translate to actual training throughput?
I run the experiments on Open-R1 dataset with this SkyPilot YAML.
| Network Type | Raw Bandwidth | Average Time per Step | Total Training Time |
|---|---|---|---|
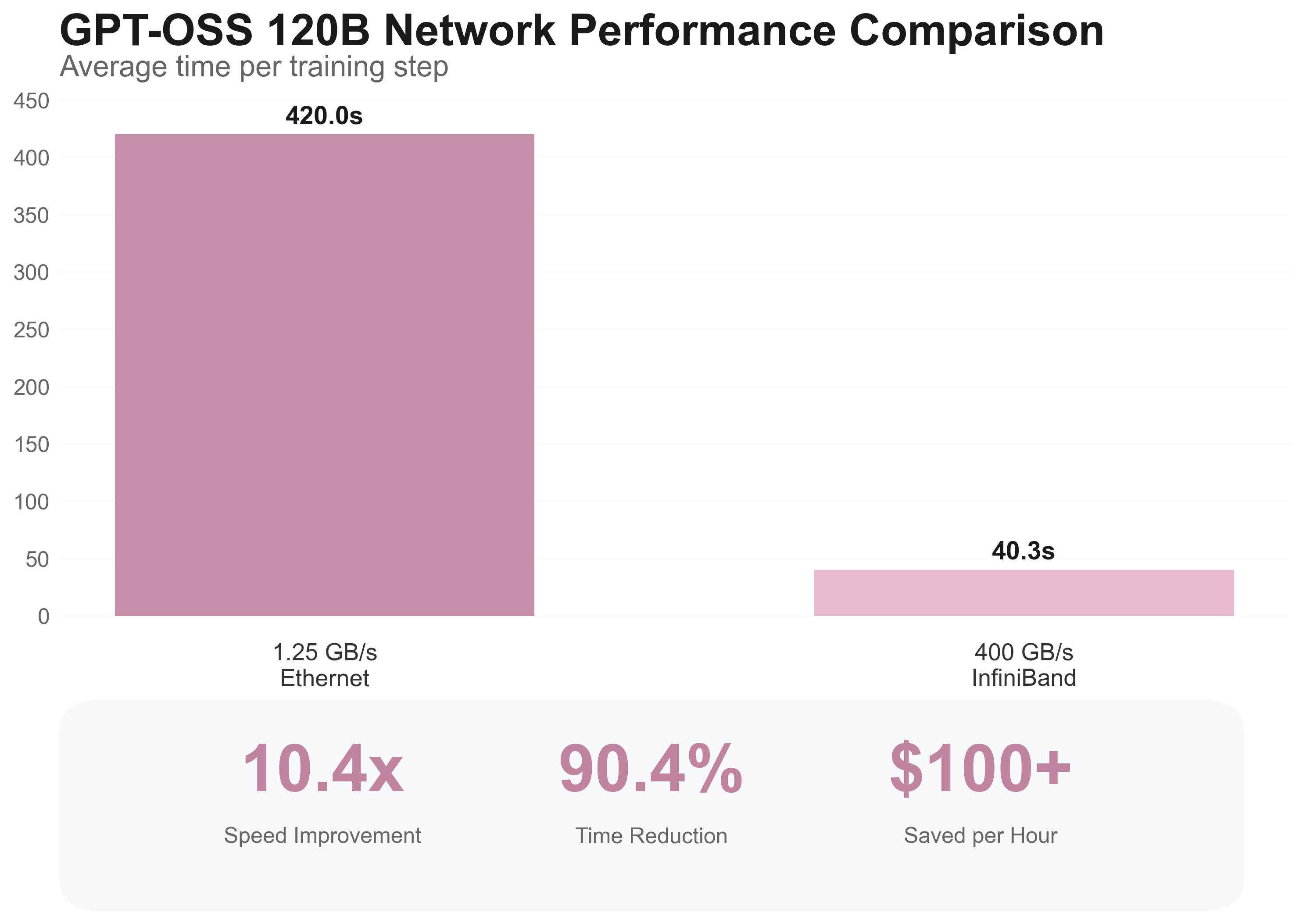
| 10 Gbit Ethernet | ~1.25 GB/s | 39.8 seconds | 53 minutes |
| NVIDIA Quantum-2 InfiniBand | ~400 GB/s | 4.4 seconds | 7 minutes |
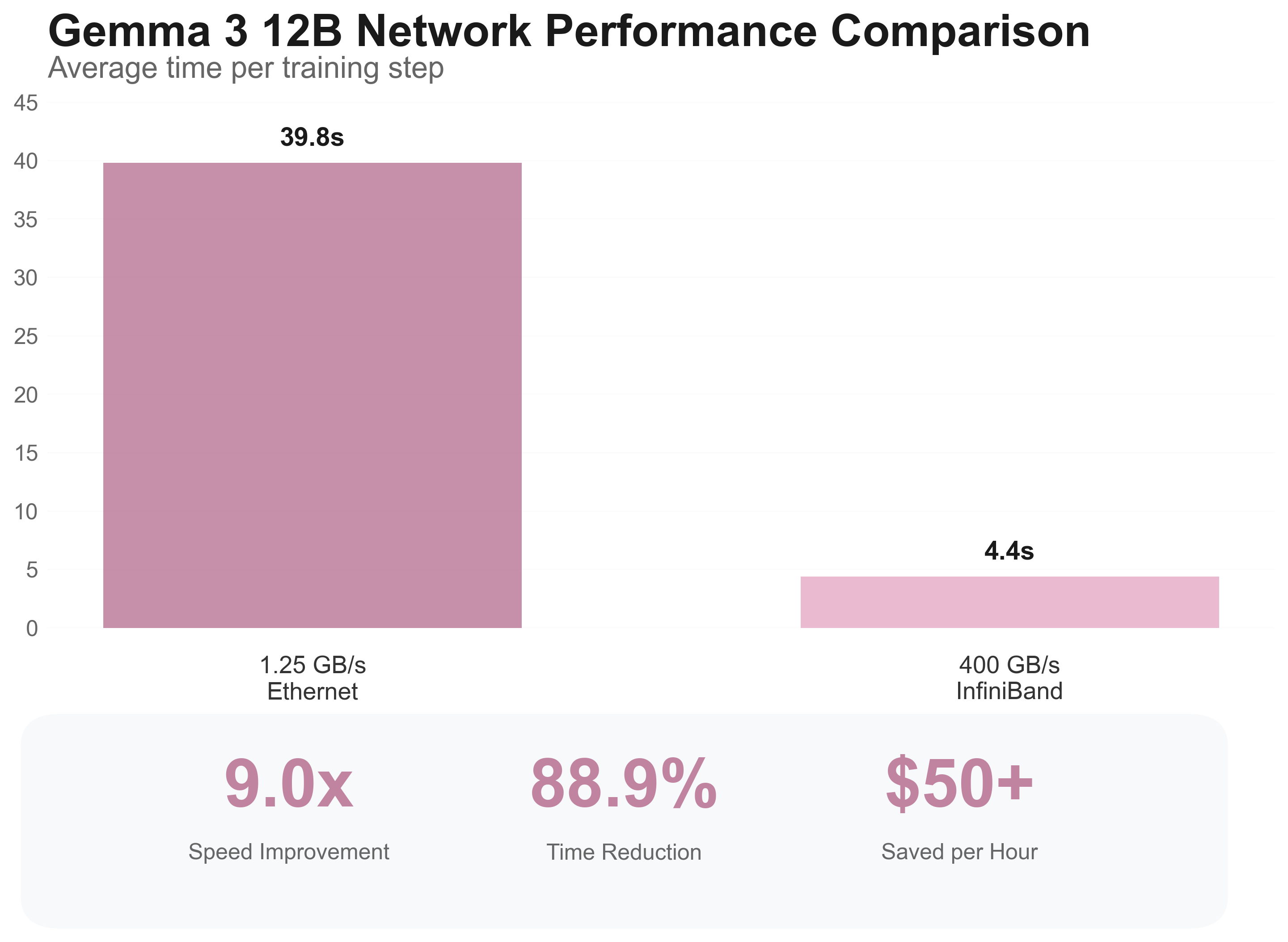
That’s a 9x speedup from network configuration alone. When you’re paying premium rates for GPU time, this isn’t just a performance improvement—it’s a cost optimization strategy.
With the GPT-OSS-120B model (10x larger!), we see the same effect - 10x speedup!
Normally, configuring high-performance networking takes a lot of effort, e.g., manual tuning many different cloud configs and setting various environment variables.
Here, SkyPilot takes care of the complexity under the hood with a single flag in the SkyPilot YAML:
name: distributed-training
resources:
accelerators: H100:8
# Enable high-performance networking for distributed training
network_tier: best
The network_tier: best flag automatically provisions InfiniBand networking (400GB/s) when available. Without this entry, the cluster uses the default network (10GB/s interface)
Profiling the network performance difference
To check how the network affects the training performance, we take a closer look at the training step when profiled in detail:

The execution breaks down into CPU work (data loading, kernel launches) and GPU work (computation plus network communication). GPU time itself divides between pure computation and communication overhead.
Comparing Ethernet versus InfiniBand configurations:

The profiles appear similar when scaled, but the crucial difference is absolute timing: 4 seconds per step with InfiniBand versus 40 seconds with Ethernet.

If we take a close look at the start of the backward pass, we can observe that with InfiniBand, the ReduceScatter operation takes just 21ms instead of 258ms (matching our 10x end-to-end performance difference).
Storage benchmarks: The hidden bottleneck
I also evaluated different storage configurations available on Nebius:
| Storage Type | Read Speed | Write Speed | Notes |
|---|---|---|---|
| Local NVMe | 10+GB/s | 10+GB/s | Fastest but non-persistent |
| Nebius Shared Filesystem | 6.4GB/s | 1.6GB/s | High-performance persistent storage |
| Object Store (MOUNT) | 300MB/s | 100MB/s | Direct S3-compatible mount |
| Object Store (MOUNT_CACHED) | 300MB/s | 300MB/s | SkyPilot's cached object store mounting |
Here’s how to configure all storage types in a SkyPilot YAML:
resources:
disk_tier: best # Provisions high-performance local NVMe
disk_size: 2000 # Size in GB
file_mounts:
/checkpoints_s3:
source: s3://your-bucket
mode: MOUNT # Direct S3 mount
/checkpoints_cached:
source: s3://your-bucket
mode: MOUNT_CACHED # Local caching + object store persistence
volumes:
/mnt/data: nebius-pvc # Mount Nebius shared filesystem
Local NVMe: Fastest but non-persistent. Configured via disk_tier: best
Nebius Shared Filesystem: High-performance persistent storage via volumes field in the SkyPilot YAML.
Object Store (MOUNT): Direct S3 mounting. Cost-effective but high-latency.
Object Store (MOUNT_CACHED): Local caching with object store persistence. Best balance of speed and durability.
End-to-end storage performance impact
For the Gemma 3 12B model training, storage performance significantly impacts different phases.
There are three different graphs: Checkpoint saving, model loading, and loading a batch from storage to train.
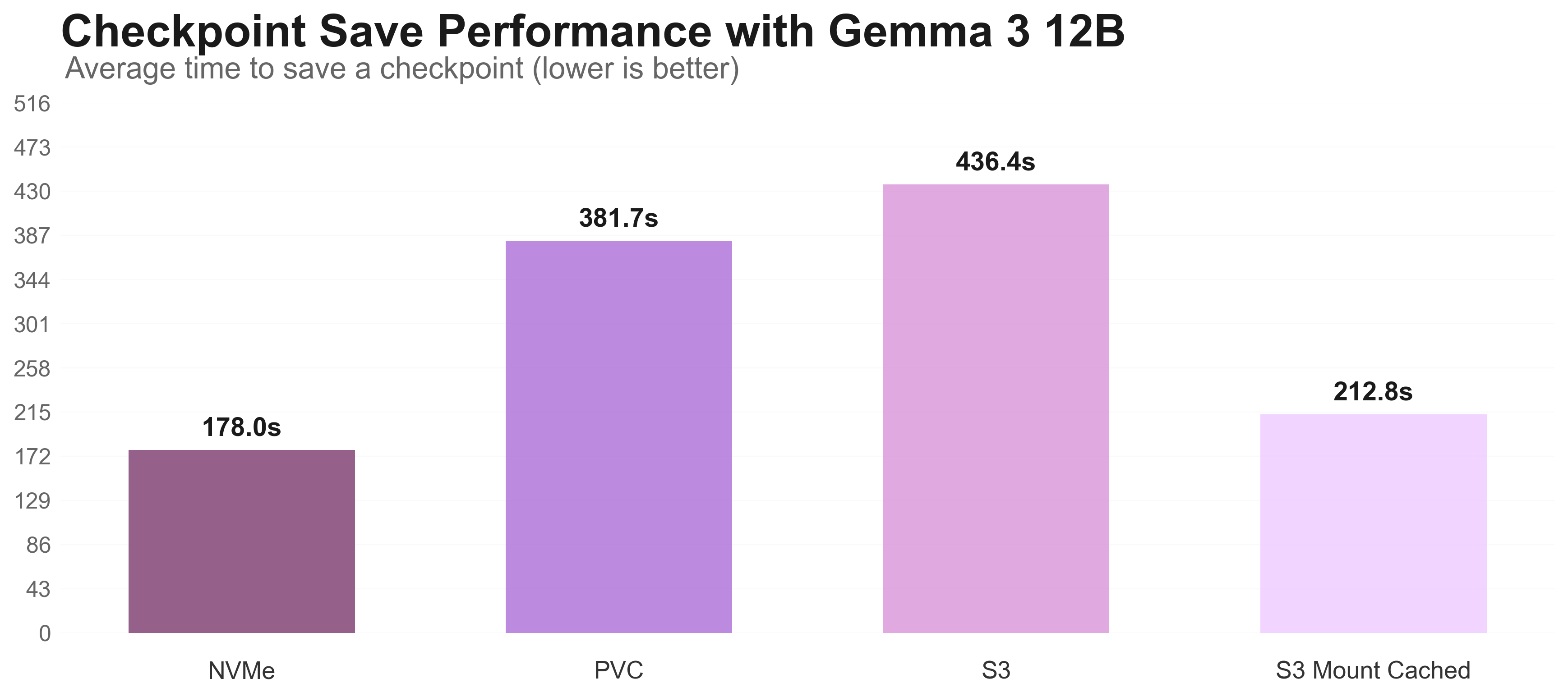
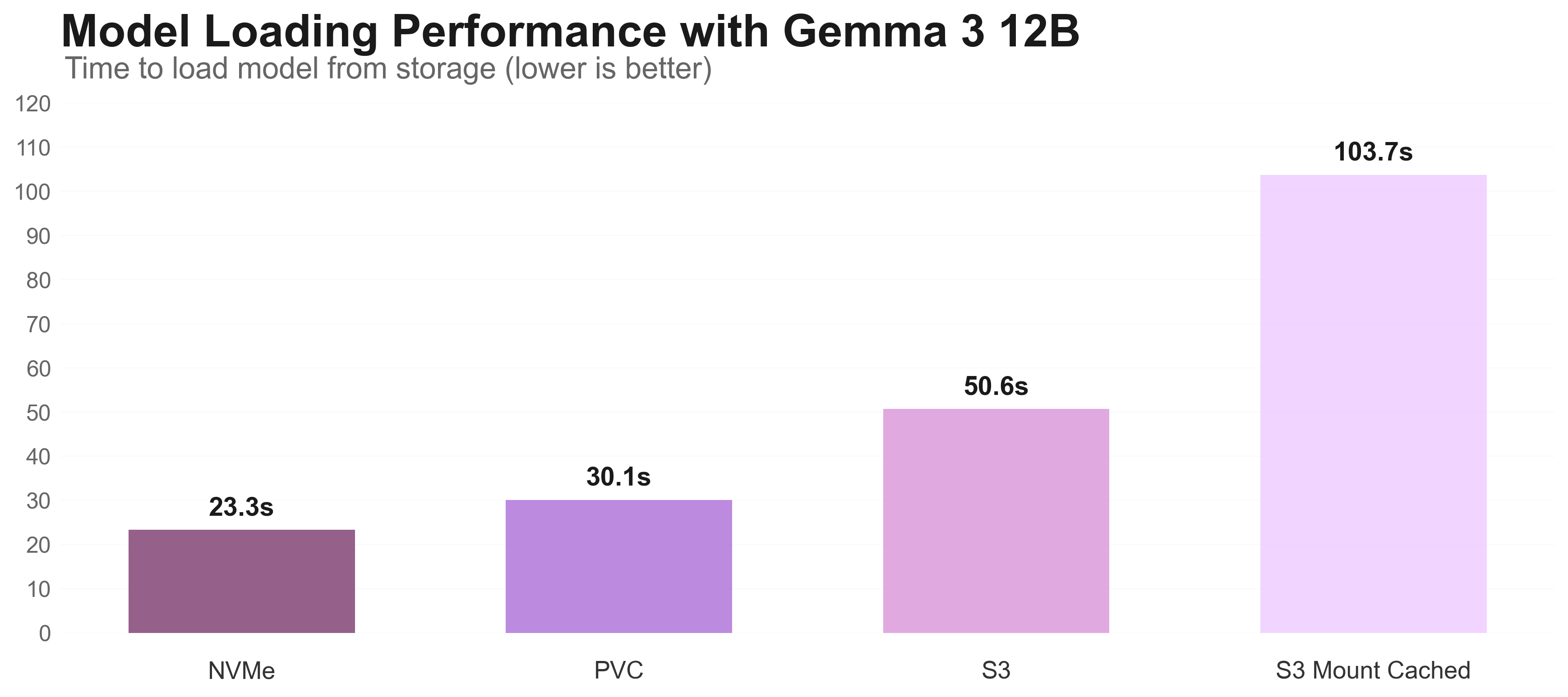
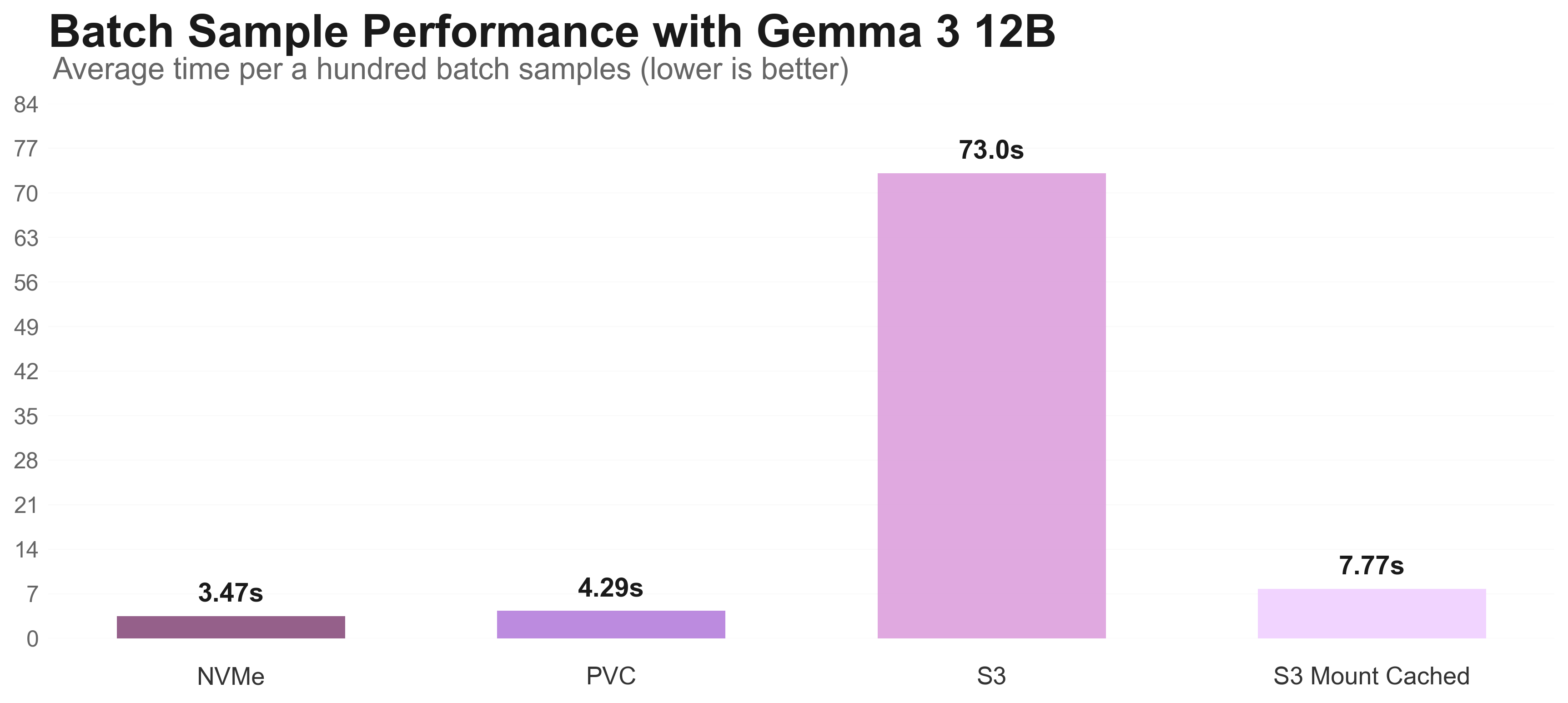
In all three, we can see that the local NVMe performs the best, but isn’t durable and is limited in capacity. The solution lies in strategic storage allocation based on workload phase requirements.
Storage performance summary
| Storage Type | Batch Loading (per 100 samples) | Model Loading | Checkpoint Saving | Persistence | Best Use Case |
|---|---|---|---|---|---|
| Local NVMe | 3.47s ⭐ | 23.3s ⭐ | 178s ⭐ | ❌ No | Temporary files intermediate checkpoints |
| Nebius Shared Filesystem | 4.29s | 30.1s ⭐ | 382s | ✅ Yes | Final checkpoints model weights |
| MOUNT | 73.1s ❌ | 50.6s ❌ | 436s ❌ | ✅ Yes | Cold storage model weights |
| MOUNT_CACHED | 7.77s ⭐ | 104s ❌ | 212 ⭐ | ✅ Yes | Training datasets checkpoints |
Click to view detailed disk performance analysis
The following image is a checkpointing saving profile of S3:
Best storage choices for each phase in training
With the benchmark results, we can figure out the best storage choices for each phase in distributed training.
The choice is not necessarily using the best storage for all the phases, because of one constraint: “Checkpoint saving” storage should be durable and the same as “model loading” storage, so previous checkpoints can be loaded when training is resumed.
I summarize the best storage choices for each phase in training:
- Batch Sampling: Nebius Shared Filesystem (4.29s)
- Model Loading: Object Store (MOUNT) (50.6s)
- Checkpoint Saving: Object Store (MOUNT_CACHED) (212s)
Here’s an example of a SkyPilot configuration using the best storage choices for each phase:
name: distributed-training
resources:
accelerators: H100:8
# High-performance InfiniBand networking
network_tier: best
num_nodes: 2
workdir: .
volumes:
# Loading dataset from the Nebius shared filesystem
/dataset: nebius-pvc
file_mounts:
# Loading model from the MOUNT storage for faster loading
/model:
source: s3://your-bucket
mode: MOUNT
# Fast checkpoint loads and saves with persistence
/checkpoints:
source: s3://your-bucket
mode: MOUNT_CACHED
setup: |
uv pip install -r requirements.txt
run: |
python train.py \
--model-path /model \
--data-path /dataset \
--checkpoint-dir /checkpoints
Network and Storage Summary
Network is critical for distributed training:
- InfiniBand vs Ethernet: 10x faster training (4.4s vs 39.8s per step)
Storage matters for different training phases:
- NVMe vs slow storage: 3.47s vs 73.1s batch loading (20x faster)
- Checkpoint saving: 178s (NVME) vs 436s (S3) (2.5x faster)
- Wrong storage = 12.1% potential training time wasted on I/O (436s/1hr = 12.1%)
End-to-end performance comparison
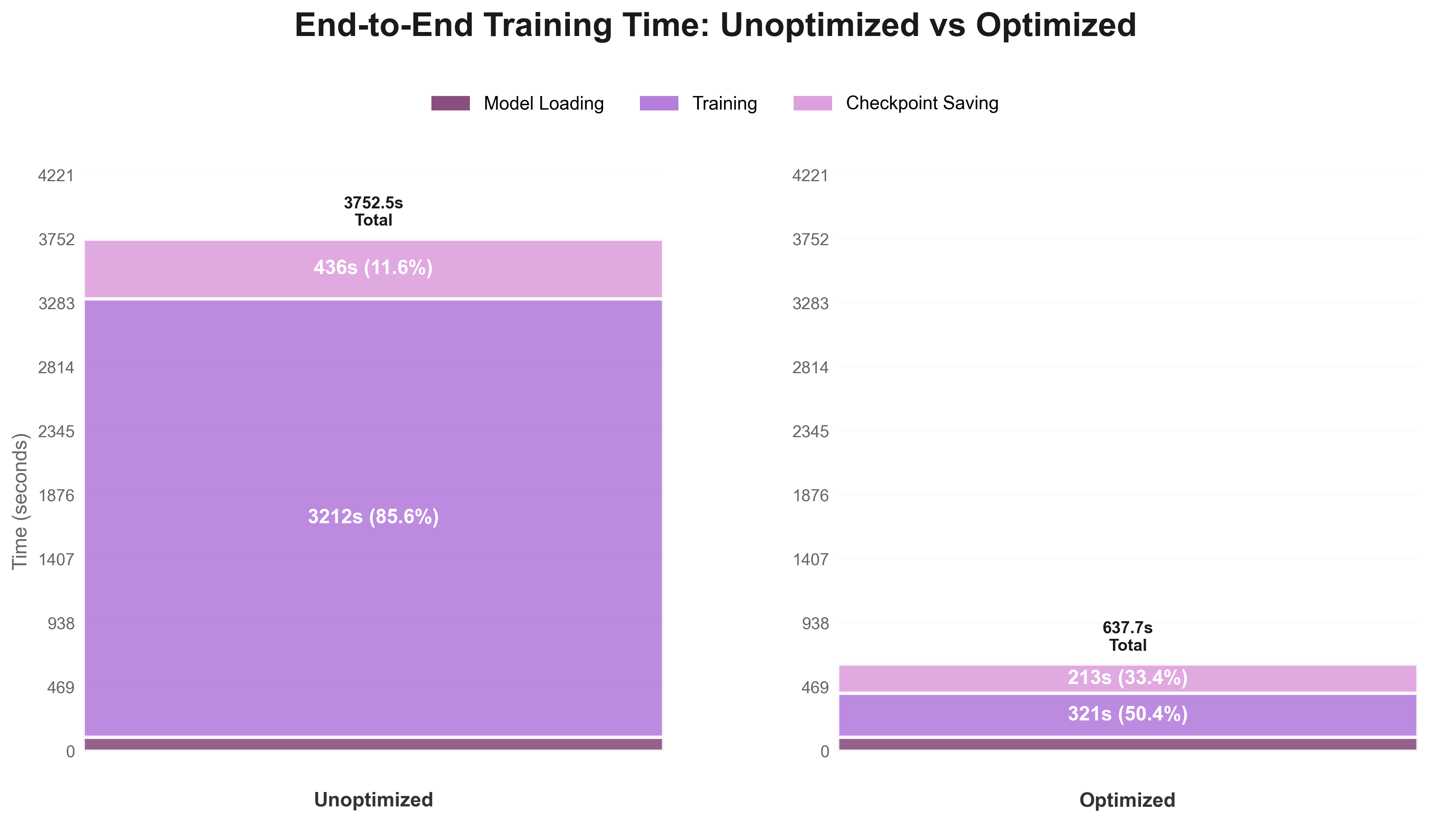
To demonstrate the cumulative impact of our optimizations, I compared two complete configurations on 80 training steps with the Gemma 12B model:
| Component | Unoptimized Configuration | Optimized Configuration |
|---|---|---|
| Model Loading | S3 | S3 MOUNT_CACHED |
| Checkpointing | S3 | S3 MOUNT_CACHED |
| Networking | Standard 10 Gbit Ethernet | InfiniBand high-performance |
The results show approximately 6-7x faster end-to-end training performance when combining optimal network and storage configurations.
Additional struggles with model training frameworks
While this blog focuses on infrastructure configuration, it’s worth addressing a broader challenge: large-scale distributed training is difficult at the software level as well based on my experience.
Based on some experience training models at limited scale, the current framework ecosystem can be visualized as a layered stack:

There are different frameworks at each level, each with their own pros and cons.
High-level frameworks are easy to configure but hard to debug when things go wrong. You often end up trying different settings until something works.
Lower-level frameworks give you more control but require more technical knowledge to use effectively.
SkyPilot handles the cloud infrastructure setup, so you don’t have to worry about that complexity.
Here’s what the debugging experience looks like when fine-tuning large models (400B+ parameters) to achieve reasonable GPU utilization and performance:

Top Layer (High-level frameworks):
- Easy to configure but hard to debug when things break
- Errors require digging through multiple abstraction layers
- Often leads to trial-and-error configuration changes
Middle Layer (Distributed frameworks):
- Mix of configuration and code required
- Generally works well and remains debuggable
- Examples:
- Enabling profiling in Accelerate requires writing code
- FSDP in Accelerate has limited configuration options (not fully supporting features like async checkpointing)
- Occasional issues with model-specific settings not working well with some parts of config (ex,
fsdp_state_dict_type: FULL_STATE_DICTwith gpt-oss)
- PyTorch knowledge helps debug failures and switch dependencies (e.g., when specific attention config override cause crashes, you know switch to another or to default eager implementation)
Bottom Layer (Low-level components):
- Avoid unless optimizing for last percentage points of performance
Conclusion
The performance differences I’ve shown highlight why infrastructure choices matter so much for distributed training. Network and storage configurations can easily create 6-7x performance differences, directly impacting both training time and costs.
SkyPilot abstracts away much of this complexity while giving you control over the performance-critical components. All the network and storage configurations I’ve discussed can be easily specified in a SkyPilot YAML files. For more details on optimizing your training infrastructure:
- Network optimization: See the SkyPilot network tier guide for configuring high-performance networking across cloud providers
- Storage performance: Check out the SkyPilot high-performance checkpointing guide for optimizing data loading and model saving
Code and benchmarks: All training scripts and benchmark code used in this guide are available in the SkyPilot examples repository.
Disclosure
This analysis was conducted during a summer collaboration with SkyPilot
Enjoy Reading This Article?
Here are some more articles you might like to read next: